생활코딩 sql강의를 통해서 sql을 벼락치기 해보자. (코테에서 한 문제는 꼭 나오기 때문에..)
https://opentutorials.org/course/1
생활코딩
hello world 생활코딩의 세계에 오신 것을 환영합니다. 생활코딩은 일반인들에게 프로그래밍을 알려주는 무료 온라인, 오프라인 수업입니다. 어떻게 공부할 것인가를 생각해보기 전에 왜 프로그
opentutorials.org
데이터 베이스 : 데이터를 저장하는 곳.
관계형 데이터베이스
: mysql, oracle, mssql
-> sql이라는 문법을 공유한다. (표준화된 문법을 공유)
nosql
: mongoDB
데이터베이스 구성
데이터베이스 서버 > 데이터베이스 > 테이블 (행, 열) > Field (행과 열의 교차점 = 한 칸)
- 데이터베이스 서버 : 전체. 데이터베이스의 집합
- 데이터베이스 : 데이터들을 카테고리로 정리. 테이블의 집합
- 테이블 : 데이터의 집합. 행열의 형태로 존재
- 필드 : 행 열의 교차점에 존재하는 데이터
: 서버의 구성방식은 클라이언트가 접근하는 순서가 된다.
데이터베이스 클라이언트 (navicat, mysql-client 등)
: 데이터베이스 서버에 접근하는 방법 혹은 도구
* sql 쿼리는 대소문자를 구분하지 않는다. -> 편할대로 써라
* 파이썬이 아니다!!!! 세미콜론 꼭 붙여라 ;;;;; -> 안그러면 화살표(->) 한 줄 더 나오면서 더 칠거 있냐는 식으로 시비틈

MySQL 실행 (WSL 기준 https://docs.microsoft.com/ko-kr/windows/wsl/tutorials/wsl-database )
- sudo /etc/init.d/mysql start : sql 서버 시작하기
- sudo mysql : 실행하기
데이터베이스 서버 레벨 명령어
- show databases; : 데이터베이스를 모두 보여달라!
- CREATE DATABASE [DATABASE NAME] CHARACTER SET utf8 COLLATE utf8_general_ci ;
: [DATABASE NAME] 으로 데이터베이스를 만드는데 문자열 세팅을 utf8로 하고, .... 나머진 모름
- drop database [DATABASE NAME]; : 데이터베이스 삭제하기
- use [DATABASE NAME] ; : [DATABASE NAME]을 사용하겠다.
- exit : 종료 (어느 레벨에서든지 사용가능. 애매헤서 여기에 넣었음. Bye가 리턴되는게 너무귀여움)
*명령어가 아닌 부분 (데이터베이스 이름 등)을 작성할 때는 억기호 ( ` ) 를 사용해야 한다는데 안해도 잘 된다..
음...? 어떡하지?
데이터베이스 레벨 명령어
- show tables; : 해당 데이터베이스가 가지고 있는 테이블들 보여줌
- create table 'tablename' ( : 테이블 생성
'title' varchar(255) NOT NULL; ) : 컬럼을 생성하는 방법
- insert into tablename (columns ... ) values (values .... ) : 해당 테이블의 컬럼에 맞춰 값을 넣는다 (row 추가)
* 스키마(schema) : 테이블에 적재될 데이터의 구조와 형식을 정의 하는 것. -> 정의에 따라 데이터를 적재해야한다.
컬럼의 이름을 정한다거나, 컬럼에 들어가야하는 데이터의 형식, null 존재 여부 등 데이터의 설계도를 작성하는 것.
- create table table_name ( 여기에 들어가는게 스키마! : 데이터 테이블 생성
column1 data_type,
)
- desc `테이블명` : description. 테이블을 요약해서 보여달라 -> 테이블의 스키마를 보여줌
- drop table `테이블명` : 테이블 삭제
- select * from `table_name` : 테이블에 있는 모든 데이터 가져오기
데이터 타입 (중요한거만!)
문자
- CHAR() : 0 to 255 고정문자길이
- VARCHAR() : 0~255 가변문자길이 (variable character)
- TEXT : 65535길이
- BLOB : 65535길이
숫자
- TINYINT() : -128 ~ 127 정수형 or 0~255 unsigned(음수사용불가옵션) *대충 8비트 연산인듯 하다.
- INT() : 정수
- FLOAT() : 작은 부동소수점
시간
- DATE : YYYY-MM-DD
- DATETIME : YYYY-MM-DD HH:MM:SS
기타
- ENUM () : 정해진 값을 강제할 때 -> 선택지가 있는 데이터를 사용할 때.
ex) enum("남자", "여자") -> 둘 중 하나의 값만 삽입할 수 있게 한다.
테이블 명령어
삽입
- insert into table_name values (values ... ); : 테이블 구조의 컬럼 순서대로 적을 것
- insert into table_name (columns ... ) values (values ... ); : 컬럼의 순서와 값의 순서가 정확히 일치할 것
변경
- update 테이블명 set 컬럼1=컬럼1에 적용할 값, 컬럼2 ... where 대상이 될 컬럼명=컬럼값 ;
: 테이블을 업데이트 하는데, where이하에 존재하는 조건을 달성하는 row들을 set이하에 존재하는 데이터로 변경한다.
그러니까 where가 조건부 선택이고, set이 데이터를 변경하는 행위이다.
- update 테이블명 set 컬럼=컬럼데이터; : 이렇게 진행하면 (where문 없이=조건없이) 모든 row에 업데이트를 적용한다.
삭제
- delete from 테이블명 where 조건; : 행 기준으로 삭제
- delete from 테이블명 (조건없이); : 전체 삭제
- truncate 테이블명; : 테이블의 전체 데이터를 삭제
- drop table 테이블명; : 테이블 삭제
조회 : 사실 데이터베이스 사용의 주 목적은 데이터 조회에 있다고 봐도 될 듯 하다. 조회가 가장 중요!
- select 칼럼1, 칼럼2 ... | * : 칼럼별 조회 | 전체조회
- [ from 테이블명 ] : where 로 조건을 걸어줄 수도 있다.
limit으로 갯수를 제한할 수 있다. (limit 1 : 갯수제한) (limit offset , count : 범위제한)
- [ group by 칼럼명 ]
- [ order by 컬럼명 [ asc | desc ] ]
- [ limit offset, 조회 할 행의 수 ]
그룹핑 (group by)
- select * from 테이블명 group by 그룹핑 할 기준 칼럼명
: 특정 칼럼을 기준으로 그룹핑을 한다. (set으로 만든다고 생각하면 좋다.) 그룹핑을 하면서 *부분에 다양한 연산을 진행할 수 있다. sum, avg 등
정렬 (order by)
- select * from 테이블명 order by 정렬의 기준으로 사용할 열 [ desc | asc ]
: order by 뒤의 열을 기준으로 내림차순(descending) 혹은 오름차순(ascending)으로 정렬된다. 그 뒤에 추가적인 기준을 더해줄 수 있다. (첫번째 기준에서 동일한 순서가 된다면 두번째 기준이 적용되는 순)
색인 (index)
: 자주 조회되는 칼럼, 조회시 오랜 시간을 소모하는 칼럼에 주로 적용. 데이터가 긴 경우에는 사용하지 않는다.
primary key
- 테이블 전체에서 중복되지 않는 값을 지정
- where문을 이용해서 데이터 조회시 가장 빠름
- 테이블마다 딱 하나의 primary key를 가질 수 있다.
- primary key (`column`), : 형태로 테이블 생성시 설정가능. (딱 하나만 정의할 수 있다.)
unique key
- primary와 동일. 유일값.
- 여러개의 unique key를 지정할 수 있다는 창.
- unique key `key_name` (`column`) : 여러개 정의할 수 있다.
normal key
- 중복 허용
- 속도가 느림(primary, unique보다)
- 여러개의 키를 지정할 수 있음
- key 'key name' ( `column` ), : 여러개 정의할 수 있다.
full text
- 일단 잘 모르겠음. 경우에 따라 적용이 안된다고 함
primary key > unique key > normal key 순으로 중요도가 존재한다고 볼 수 있다.
조인 (join) : 확실히 어렵다!..
: 데이터의 규모가 커질수록 테이블이 많아지기 때문에 존재하는 기능.
- outer join : 매칭되는 행이 없어도 결과를 가져오고 없는 경우는 NULL
- left join : 가장많이 사용되는 형태.
|
SELECT s.name, s.location_id, l.name AS address, l.distance FROM student AS s LEFT JOIN location AS l ON s.location_id = l.id;
|
AS : alias 파이썬 as 처럼 쓴다.
ON : 결합의 조건
- right join :
- inner join : 두개의 데이터 테이블 모두에 데이터가 존재하는 행에 대해서만 결과를 가져옴
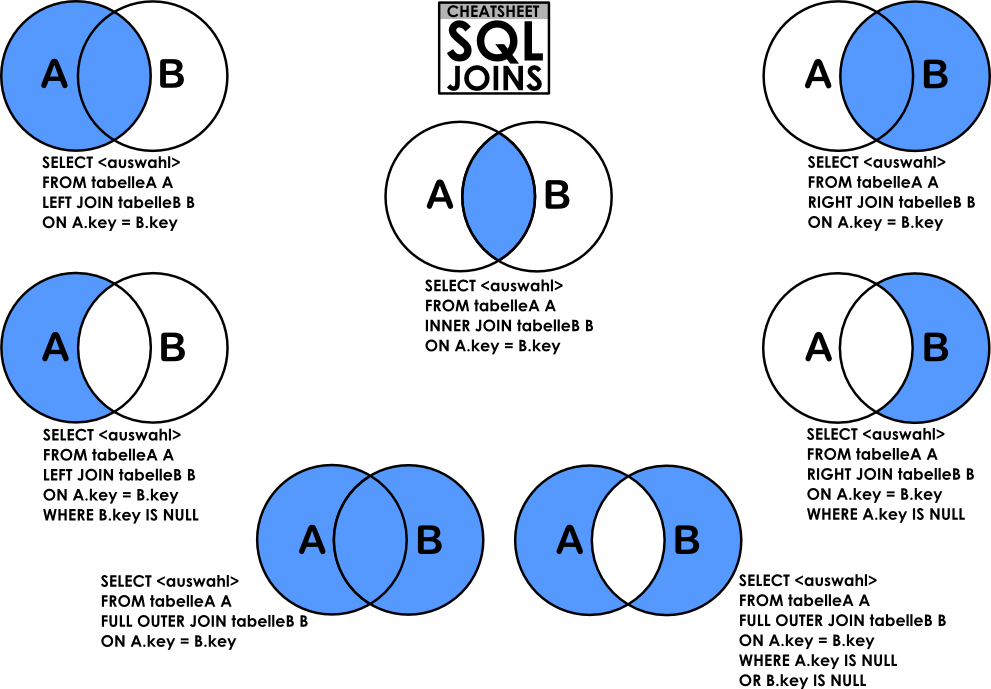
innder join, left join, 순으로 많이 쓴다. full outer는 진짜 잘 안씀.
아 알고보니까 SQL은 JOIN이 제일 어렵다. 이런 이유로 생활코딩에서도 JOIN에 대한 강의가 별도로 존재한다.
* 관계형 데이터베이스의 핵심기능이라고 한다.
https://opentutorials.org/course/3884
SQL Join - 생활코딩
수업소개 관계형 데이터베이스에서 테이블과 테이블의 관계를 이용해서 새로운 테이블을 만들어내는 태크닉인 join을 알려드리는 수업입니다. 이 수업은 아래와 같은 내용을 다루고 있습니다.
opentutorials.org
* 트레이드 오프(trade off)라는 현실에서 장점만 가진 환상을 만들어 내는 것이 공학의 미학이다.
걍 인상적인 구절이라 적어봤음. There's no Tarade off.
JOIN 배우기
1. LEFT JOIN (LEFT OUTER JOIN)
: 첫 번째 테이블에 존재하는 열을 기준으로 행들을 추가한다. 때문에 두번째 테이블에서 넘어온 행 중에 NULL값을 가진 필드들이 있다. RIGHT JOIN 같은 경우는 여기서 B집합 영역만 취하는 경우이다.
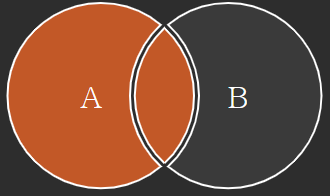
이미지 출처 : https://sql-joins.leopard.in.ua/
- SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.id;
: table1의 오른쪽에 table2를 붙이는데, 기준은 id가 동일한 경우로 한다. 이런 형태를 다중으로 구현할 수 있는데
- SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.id LEFT JOIN table3 ON table2.id = table3.id;
: 원리는 크게 다르지 않다.
2. INNER JOIN
: 양쪽 모두에 존재하는 행만 가지고 새로운 테이블을 만드는 기능 (교집합). 따라서 NULL 행이 존재하지 않는다.

- SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.id;
3. FULL JOIN (FULL OUTER JOIN)
: 합집합 같은 형태. 하지만 많이 사용하지 않는다.

- SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.id = table2.id
: 이렇게 진행할 수 있지만 대부분의 DB에서 지원하지 않는다. 내가 사용중인 MYSQL도 마찬가지다.
- (SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.id)
UNION DISTINCT
(SELECT * FROM table1 RIGHT JOIN table2 ON table1.id = table2.id)
: 이렇게 두 테이블의 left join과 right join을 진행하고 이 둘을 UNION (합집합이란 뜻) 이라는 집합 명령어로 합쳐준다. 단, 이렇게 되면 교집합(intersection)부분이 중복되는데 이를 제거하기 위해 DISTINCT(별개의, 유일값을 의미)라는 쿼리를 추가하면 된다. 하지만 잘 쓰이지 않는건 동일하다.
4. EXCLUSIVE JOIN
: 베타적 집합. 교집합을 제외한다고 생각하면된다. 한 테이블에만 존재하는 값만 가져온다. 하지만 이 또한 잘 사용하지 않는다. 구현 방식은 FULL OUTER JOIN과 같다. LEFT JOIN에 다른 쿼리들을 추가로 조합하여 만든다.

- SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.id WHERE table2.id is NULL;
: 두 테이블을 LEFT JOIN하게 되면, 첫번째 테이블중 두번째 테이블의 행값을 갖고있지 않은 열은 NULL을 띄게 된다. 때문에 WHERE로 조건을 걸어 NULL이 존재하는 값만 가져오게 하면 한 집합 내에서 교집합을 제외한 집합, 즉 베타적 집합을 가져올 수 있다.
휴 JOIN 끝!
'Application > DataBase' 카테고리의 다른 글
| M1 Mac PostgreSQL 설치하기 (0) | 2024.05.02 |
|---|